case · 2025–present
iPlayarr.
Role
Creator & primary maintainer
Stack
- TypeScript
- Node.js
- Express
- Redis
- Socket.io
- Vue 3
- Docker multi-arch
iPlayarr
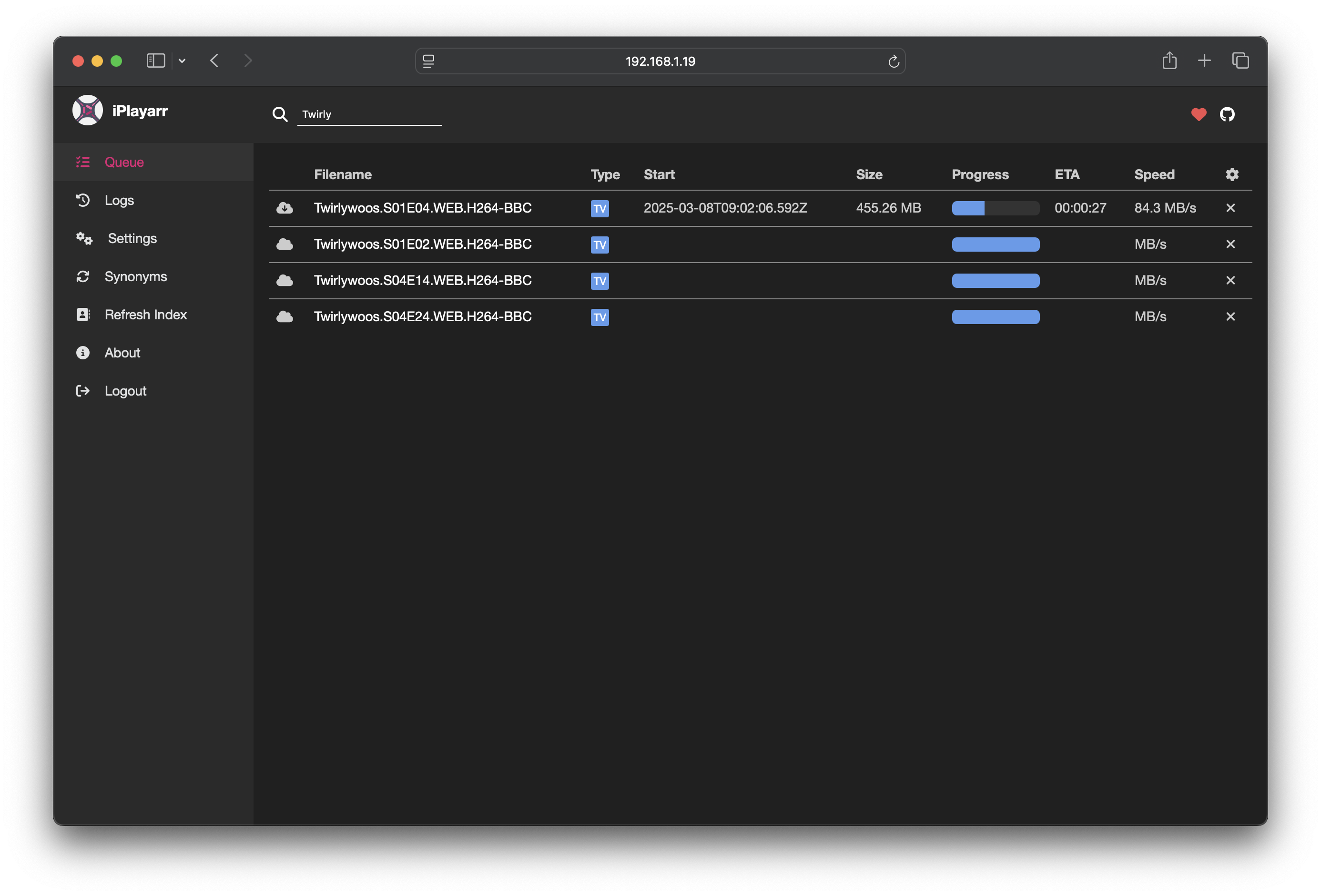
A companion for the *Arr stack that makes BBC iPlayer a first-class citizen in Sonarr and Radarr, by pretending to be two things it isn't. My first real open-source project; 120+ stars, ~225 merged PRs, and one proper second-contributor.
TL;DR
The problem: Sonarr and Radarr are the de-facto automation tools for self-hosted media libraries. They know how to talk to newznab indexers and SABnzbd-style download clients. They don't know how to talk to BBC iPlayer.
The trick: iPlayarr is one process that pretends to be both, a newznab indexer and a SABnzbd-compatible download client, and under the hood it wraps get_iplayer. Sonarr happily issues searches and "grabs", never needing to know iPlayer exists.
The point: to give Sonarr and Radarr users a legitimate alternative source for UK content they can freely stream anyway, with the same automation ergonomics as the rest of the stack.
The shape of the project:
- Backend: TypeScript + Express + Redis + Socket.io.
- Frontend: Vue 3 SPA, added once the tool outgrew being headless.
- Downloaders:
get_iplayerprimary,yt-dlpas an alternative, pluggable via a facade. - Distribution: Docker image on Docker Hub, multi-arch (amd64 / arm64 / armv7), zero-config by default (bundles a Redis binary inside the container).
- Scale: 711 commits, ~225 merged PRs, 11 contributors, 12 releases, a Discord, a Coveralls badge, and about four months from "I'll look into it" to "other people use this in anger."
Origin
I wanted a cleaner way for Sonarr and Radarr to see BBC content as a source, iPlayer is where I legally and legitimately watch most of it, and it was the obvious gap in an otherwise-automated stack.
My first instinct was the proper, upstream-friendly route: write a PR against Sonarr itself and teach it about iPlayer. Sonarr is C#, and when I actually opened the codebase it felt impenetrable, not impossible, just not a weekend's worth of ramp-up. I closed the tab.
What I did instead was work out that Sonarr and Radarr don't need to know it's iPlayer at all. They already know how to talk to:
- Newznab indexers (XML,
?t=tvsearch&q=...). - SABnzbd download clients (JSON,
?mode=queue&apikey=...).
If a single process can credibly answer both of those protocols, and do the real work of fetching content behind them, it looks like a normal indexer-plus-client pair to Sonarr. That was the insight and it was mine; I'd not seen it done for iPlayer. The rest is implementation.
First commit to "ready to be properly used": about four weeks, as a headless tool. The Vue 3 web UI came later.
(Footnote: I did end up contributing to Sonarr and Radarr upstream anyway, both merged a small PR of mine that lets users auto-tag BBC network shows so they're routed to iPlayarr rather than other indexers. The long way round worked out.)
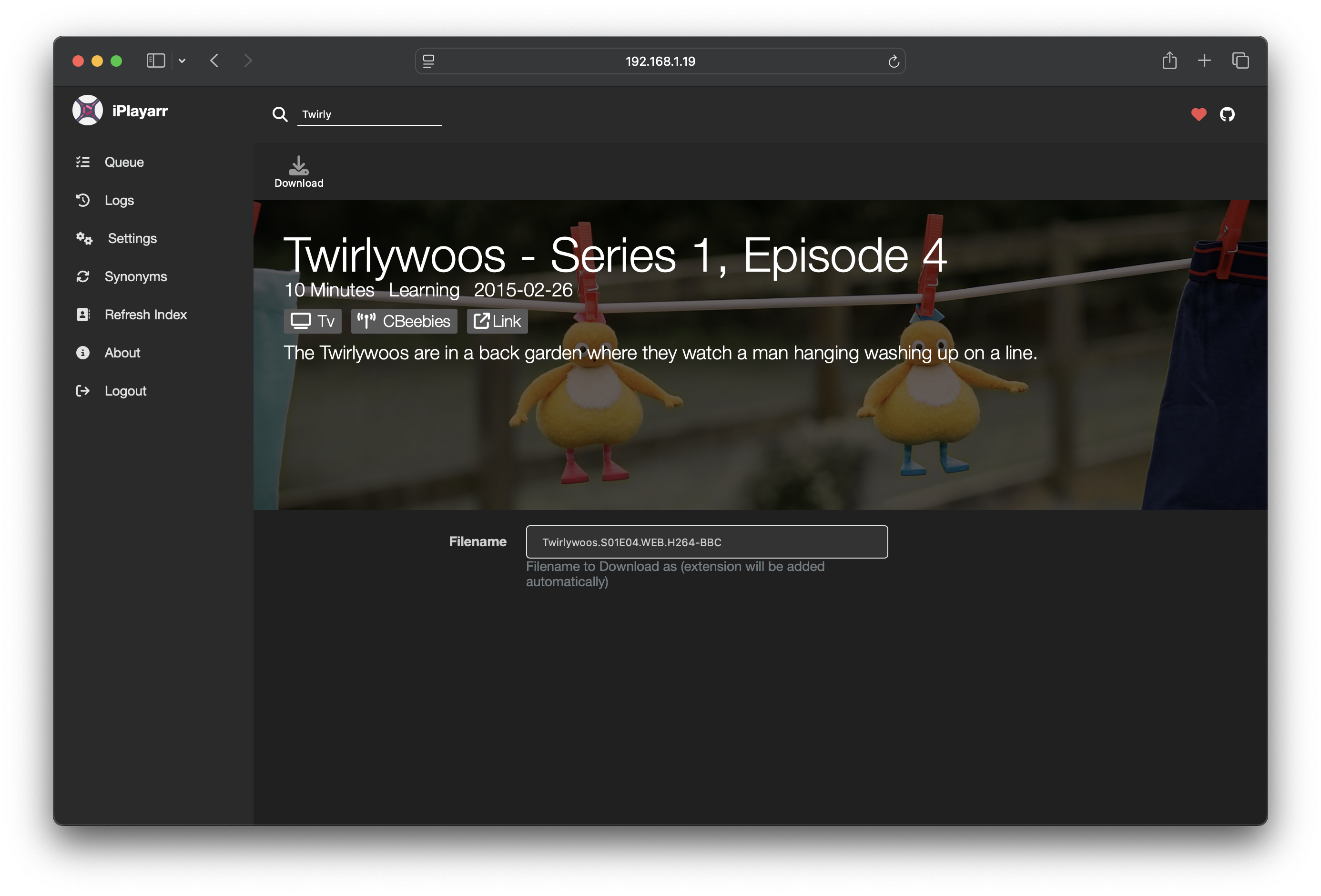
What it does, in one picture
The two facades
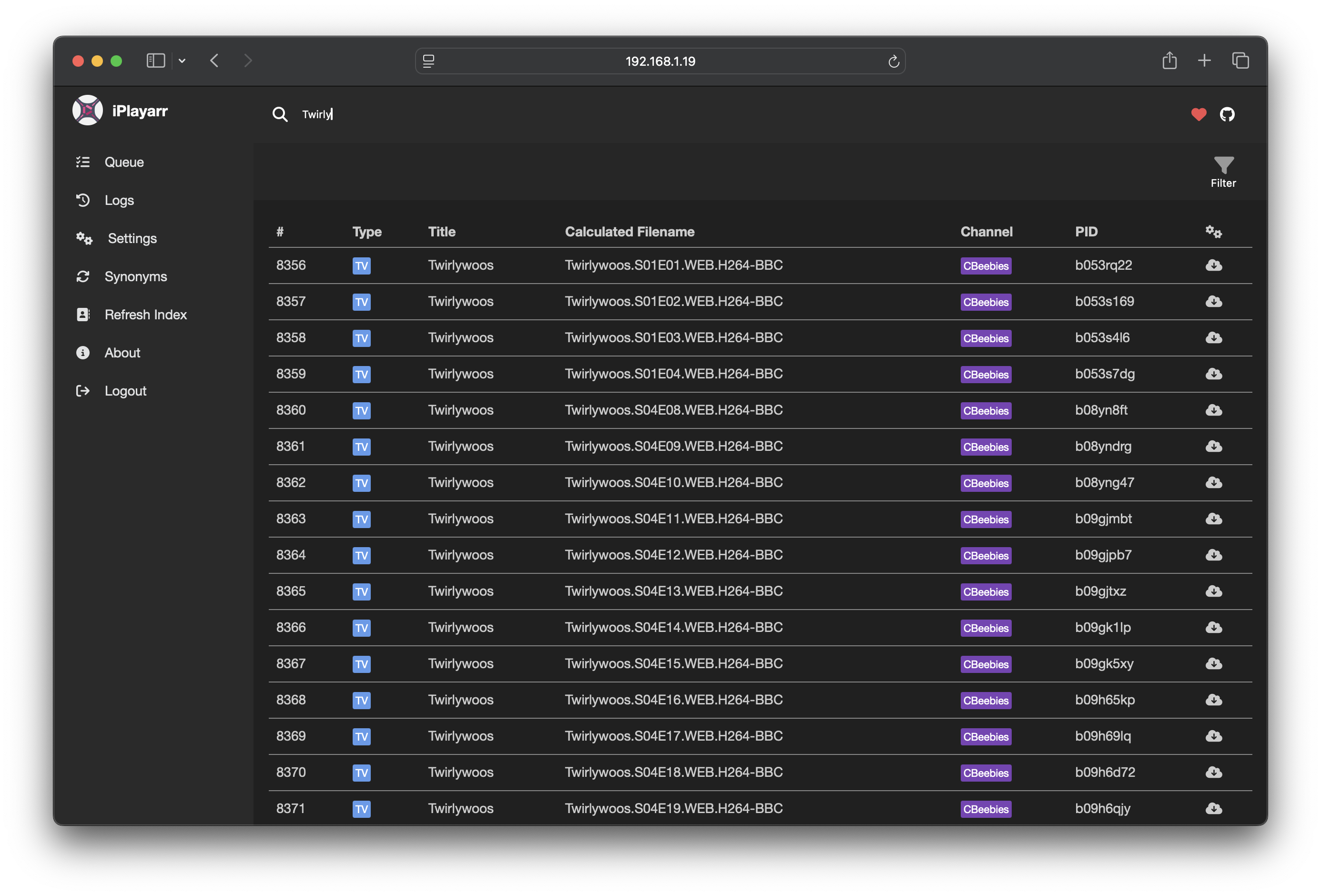
Newznab (/api?t=...)
Handled in src/endpoints/newznab/:
caps, capabilities XML (search modes, categories, max results).search,tvsearch,movie-search, RSS 2.0 responses, one<item>per iPlayer result, annotated with thenewznab:attrextensions Sonarr expects (category, language, grabs).
Category routing is the clever mapping: a single search can legitimately return TV and movie results, tagged 5000/5040 and 2000/2040 respectively. Sonarr filters to TV, Radarr filters to movies, and the same unified response serves both without either knowing about the other.
SABnzbd (/api?mode=...)
Handled in src/endpoints/sabnzbd/:
queue,history,get_config,version,addfile,nzb-download.
This is the stickier half, because "look like SABnzbd enough for Sonarr to be happy" means matching its JSON response shape precisely, including quirks. Missing fields like speed, size, sizeleft, kbpersec have surfaced as bugs over time (PR #225 was a recent contributor fix). The newznab side is XML-stable; the SABnzbd side is the one that breaks when Sonarr's expectations drift.
Why this works at all
Sonarr's model of "grab from indexer, hand to download client, poll for progress, read completed path from history" is protocol-shaped, not Usenet-shaped. If you satisfy the protocol, the plumbing doesn't care what sits behind it.
Stack
Backend
| Layer | Choice | Notes |
|---|---|---|
| Language | TypeScript | strict mode, ES2021 target |
| Framework | Express 4 | route-handler dispatch keyed by ?t= / ?mode= |
| State | Redis (ioredis) | config, history, search cache, logs, sessions |
| Realtime | Socket.io | queue + history + log broadcast to the UI |
| Auth | express-session + bcrypt; optional OIDC via openid-client | API key (newznab-style) for the machine-to-machine side |
| Process runner | child_process.spawn |
stdout line-parsing for progress |
| Search indexing | Lunr | re-ranks native BBC API results |
| Scheduling | node-cron | off-schedule pre-warming |
Frontend
Vue 3 (Options API, single-file components), vue-router, no state library, custom CSS/LESS, FontAwesome for icons, vue-final-modal for dialogs, apexcharts for the stats page, and socket.io-client for live queue/progress. Deliberately light.
Download backends
get_iplayer (Perl, bundled at build time in the Docker image) and yt-dlp (for non-iPlayer sources), both behind an AbstractDownloadService.
Packaging
- Docker Hub:
nikorag/iplayarr, multi-arch (amd64,arm64,armv7). - Bundled Redis: the image ships a Redis binary and the entrypoint starts it if
REDIS_HOSTis unset, zero-config by default, BYO-Redis for anyone who prefers it. - PUID/PGID: host UID/GID injected at runtime so bind-mounted volumes have matching ownership (the selfhost community standard).
- GitHub Actions: build-on-PR, tests + Coveralls coverage on main, Docker Hub multi-arch publish on release.
Notable decisions and subsystems
Dual search backends
There are two implementations of AbstractSearchService:
GetIplayerSearchService, spawnsget_iplayer --list, parses the output line-by-line. Authoritative but relatively slow, andget_iplayeris really designed for scheduled bulk indexing rather than per-request search.NativeSearchService, callshttps://ibl.api.bbc.co.uk/ibl/v1/new-search, re-ranks results through a Lunr index, expands containers to individual episodes, enriches from an episode-metadata cache.
Users toggle via NATIVE_SEARCH. The iBL endpoint isn't publicly documented, I reverse-engineered it out of get_iplayer's Perl source, where it turns up as the call get_iplayer itself makes for some lookups.
Native search exists because get_iplayer's design point (long-running schedule refresh) doesn't match iPlayarr's (fast per-request search). Lunr is layered on top because the raw BBC search ranking is fine for a homepage but not tuned for "does this exactly match the series Sonarr just asked for."
Both backends stay in the tree, because users get to pick the trade-off.
Skyhook and synonyms, two problems that look similar
These two systems both touch "the show on iPlayer doesn't quite match what Sonarr thinks it should be" but solve different halves of it:
- Skyhook (TVDB lookup, the same metadata source Sonarr itself uses) resolves episode numbering. When the BBC rebroadcasts a show and iPlayer lists it as Series 1 of the rebroadcast block, but Sonarr is tracking it as Series 15 of the original, Skyhook maps the release into Sonarr's numbering so the grab is accepted.
- Synonyms (custom aliases, Redis-stored) resolve titles. When Sonarr searches for "Frozen Planet II" but the BBC listing is "Frozen Planet 2" (or a different localisation entirely), a synonym entry bridges the two.
Together they cover most of the edge cases that would otherwise cause Sonarr to reject a perfectly good grab.
Queue + realtime
The queue is in-memory (a plain array of QueueEntry). On each state change, socketService.emit('queue', queue) broadcasts to all connected Vue clients; the UI re-renders from the broadcast. No polling.
- Concurrency is a simple "run up to N downloads simultaneously" counter, governed by
ACTIVE_LIMIT(default 3). - The queue doesn't survive a restart. For a self-hosted tool that's an explicitly acceptable trade: Sonarr and Radarr will re-request anything they still want. Only the history is persisted (Redis).
- Progress itself is pulled out of
get_iplayer's stdout with one serious-looking regex that tolerates unit variance (MB vs GB, KB/s vs MB/s,N/Avs numeric):
/([\d.]+)% of ~\s*(?:([\d.]+\s?[A-Za-z]+)|N\/A) @\s*([\d.]+\s?[A-Za-z]+\/s) ETA: (?:([\d:]+)|NA).*video\]$/Docker-first, zero config
The Docker image is the canonical install. It:
- Compiles the app at build time (TypeScript + Vue CLI), strips sources, keeps
dist/. - Downloads and bundles a pinned
get_iplayer(v3.35) and the latestyt-dlp. - Embeds a Redis binary from
redis:alpine. - Uses an entrypoint that starts Redis if needed, resolves PUID/PGID to a non-root user, chowns volumes, and drops to that user with
su-exec.
docker run with an API key and you have a working tool. That's the point.
What I'd change
The one I'd rip out and redo tomorrow is Redis.
The project started using node-persist, a flat JSON-on-disk KV store, easy and local. Concurrency was the killer: rapid queue/config writes raced each other and corrupted state. src/types/QueuedStorage.ts is a promise-chain that serialises all writes, and it's a hangover from trying to patch that original problem, not something I'd choose today.
The move to Redis solved concurrency cleanly. It also:
- Forced the bundled-Redis-in-the-Docker-image situation, because most self-hosters don't want to stand up a Redis instance just to run one more Arr app.
- Took on a surface area that doesn't justify itself for the actual data shape, which is overwhelmingly "config document + history list + caches with TTLs."
If I rebuilt this layer today I'd use Prisma + SQLite. One file, transactional, no separate server, no bundled binary. The change is in the backlog.
Running my first OSS project
This is the first thing of mine that has strangers' names in the commit log, and the honest summary is:
Every time I look at the issue list, part of me wants to un-publish the repo.
That's the biggest takeaway. The anxiety of public visibility is a real tax the project documentation rarely mentions. Mostly it's bugs rather than feature requests, which is the better shape of inbound, bugs have finite scopes, feature requests have infinite ones, but the sheer fact of the list existing is its own weight.
Some things that took the edge off:
- A strict code-review bar, openly set. I push back on PRs when I need to. Contributors have respected it, and the code has stayed consistent enough that it's still navigable at 711 commits in.
- A second-in-command who appointed himself. Danny Smith (StormPooper) has landed ~70 commits across synonyms, Skyhook integration, native-search fixes, and increasingly the code reviews. We don't co-ordinate like a team; he just shows up, does his own thing, and the thing he does is reliably good. That he exists at all has been the single biggest change in what this project feels like to maintain.
- Discord stays quiet, and that's fine. The server exists. It's not an active community. I'm not trying to make it one.
Launched on Reddit in two posts, one asking whether anyone was interested enough to justify building it, one announcing the result. £15 on Ko-fi so far, which is £15 more than most things I've built.
Metrics
- 120+ stars on GitHub
- 711 commits across ~13 months
- ~225 merged pull requests
- 11 contributors (Jamie 548, Danny 72, Owen 7, plus a long tail)
- 12 tagged releases on Docker Hub, latest v0.11.6
- Multi-arch Docker images (amd64 / arm64 / armv7)
- Coveralls-tracked test coverage, Jest + ioredis-mock
Links
- Repo: github.com/Nikorag/iplayarr
- Docker Hub: hub.docker.com/r/nikorag/iplayarr
- Discord: linked in the README
next case →
HobbyPCB
A shop/showcase site for my dad's 6502 and amateur-radio PCBs, with a CMS he can actually use, and a fully-functional fake terminal hidden in the menu bar.